|
Brown University |
Brown University |
Brown University |
|
|
|
| AI models are increasingly required to be multimodal, integrating disparate input streams into a coherent state representation on which subsequent behaviors and actions can be based. This paper seeks to understand how such models behave when input streams present conflicting information. Focusing specifically on vision-language models, we provide inconsistent inputs (e.g., an image of a dog paired with the caption "A photo of a cat") and ask the model to report the information present in one of the specific modalities (e.g., "What does the caption say / What is in the image?"). We find that models often favor one modality over the other, e.g., reporting the image regardless of what the caption says, but that different models differ in which modality they favor. We find evidence that the behaviorally preferred modality is evident in the internal representational structure of the model, and that specific attention heads can restructure the representations to favor one modality over the other. Moreover, we find modality-agnostic "router heads" which appear to promote answers about the modality requested in the instruction, and which can be manipulated or transferred in order to improve performance across datasets and modalities. Together, the work provides essential steps towards identifying and controlling if and how models detect and resolve conflicting signals within complex multimodal environments. |
|
|
|
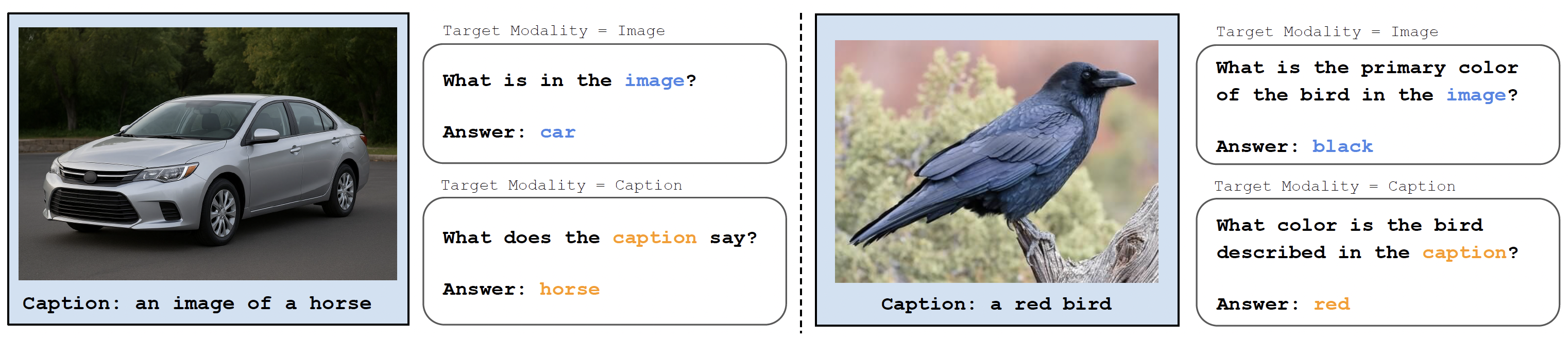
Examples of inconsistent image and caption pairs. Left: image and caption disagrees on the main object of the image. Right: image and caption disagrees on an attribute of the main object of the image. Either case, model needs to report image or caption information based on the target modality. |
|
|
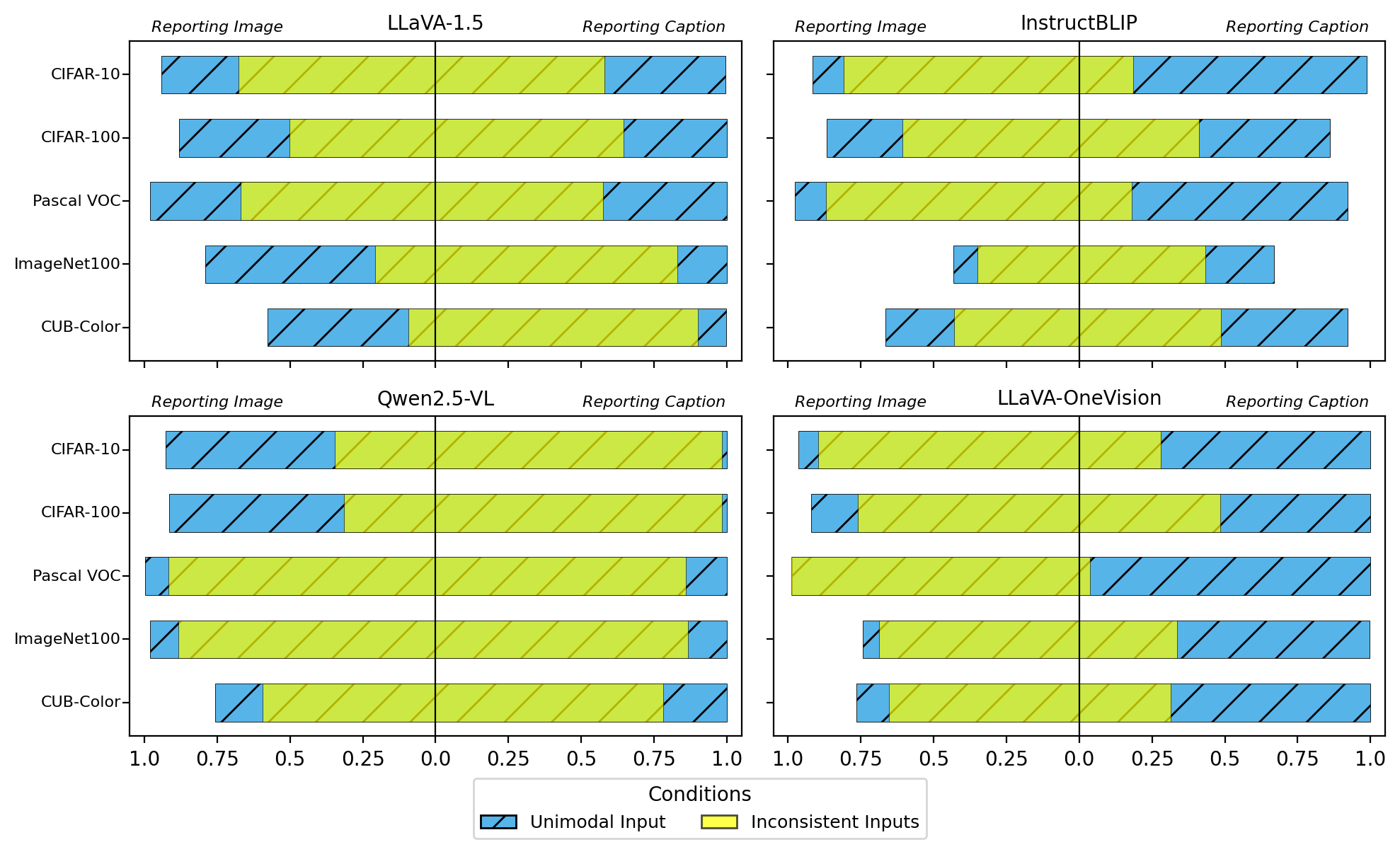
Model performance on reporting target modality information under unimodal inputs and inconsistent inputs. Horizontal bars show accuracy for each model–dataset pair when the model is asked to report either the image (left column in every panel) or the caption (right column). |
1. Do VLMs Fail to Encode Unimodal Information? |
 |
|
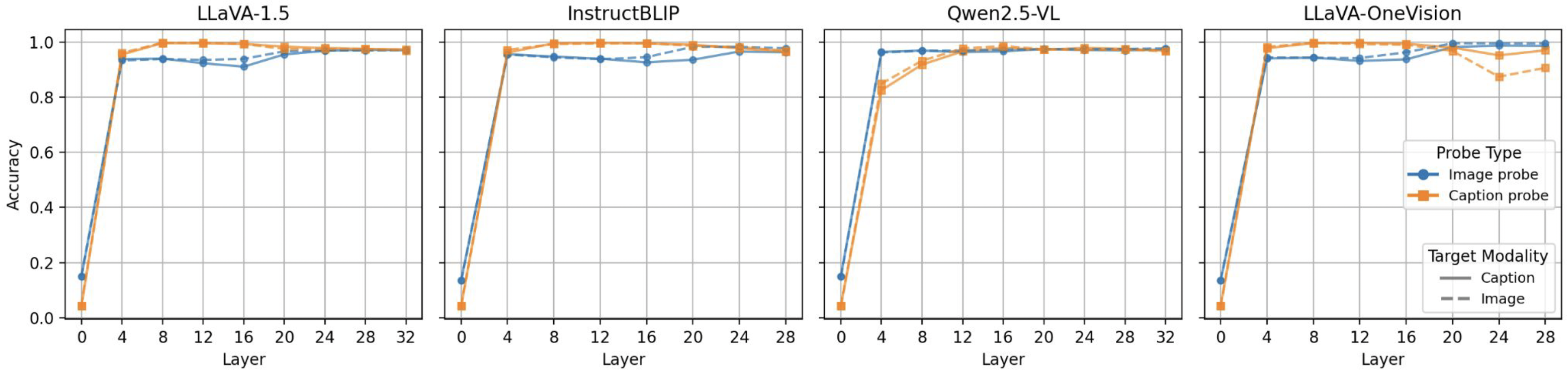
Accuracy of unimodal information probe on Pascal VOC dataset. Probe accuracies remain high on unimodal information probe on the last layers, indicating that VLMs can sufficiently encode the information of each modality. |
2. Do VLMs Fail to Detect the Inconsistencies between Two Modalities? |
 |
|
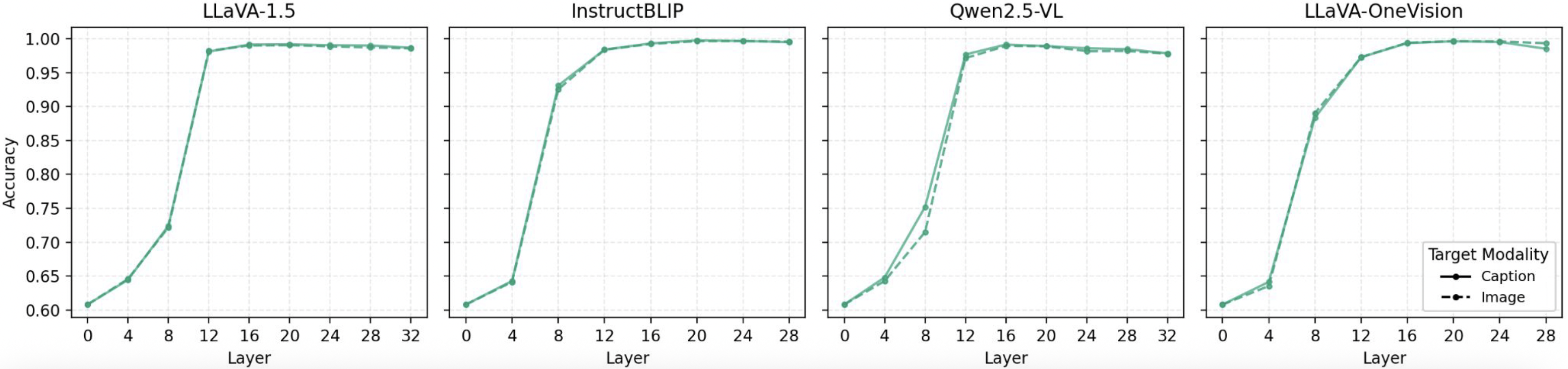
Accuracy of consistency probe on Pascal VOC dataset. Probe accuracies remain high on consistency probe on the last layers, indicating that VLMs can sufficiently encode the information of consistency between two modalities. |
3. Do VLMs Inherently Favor One Modality over Another in Representational Space? |
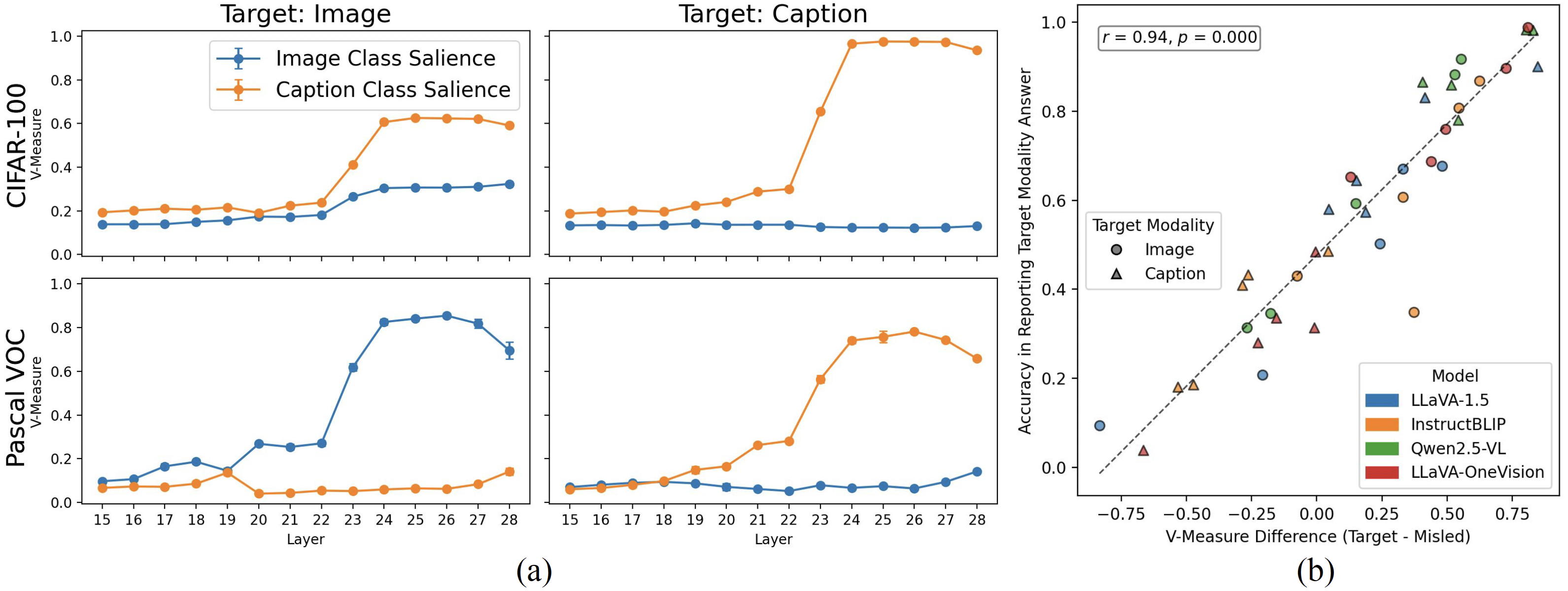 |
|
Representational salience and behavioral accuracy. (a) Layer-wise V-Measure of Qwen2.5-VL representations with regard to the image and caption labels of the inconsistent samples, on CIFAR-100 (top) and Pascal VOC (bottom); in CIFAR-100, captions are always encoded more saliently regardless of the target modality, which leads to a degraded performance for Qwen2.5-VL to report image informtion. In contrast, Qwen2.5-VL (re)organizes its representations in Pascal VOC to always align the target modality more saliently. (b) Across all model–dataset–task triples, the V-Measure gap (target − misleading) strongly predicts accuracy on the target modality (r = 0.94 , p < 0.001). In all, these patterns suggest that (1) models which perform poorly fail to (re)-organize their internal representations of the inputs in a way that is responsive to the instruction. (2) This ability to (re)cluster the inputs appears to be correlated with performance in general, across models and datasets. |
1. Modality-Agnostic Router Head & Modality-Specific Promotion Head |
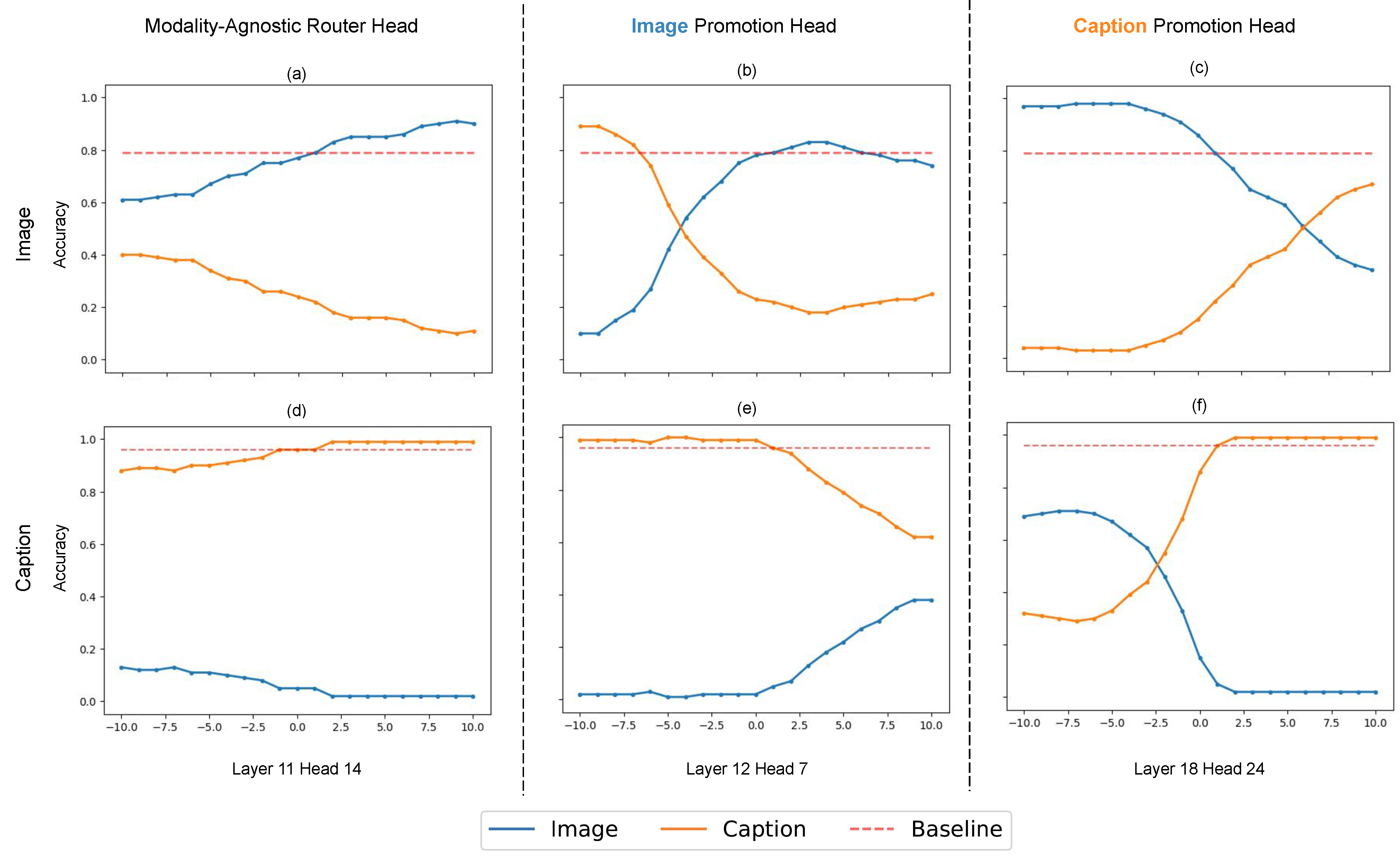 |
|
We hypothesize that there exists a competition process when model needs to selectively recall information from one modality over another. We adjust the outputs of each attention from α ranged from -10.0 to 10.0, and identify three different types of attention heads. Figure above shows examples of different types of attention heads in Qwen2.5-VL found on Pascal VOC. First row shows the results on 100 data examples requesting for image information, while second row shows those requesting for caption information. Baseline represents original model's performance without intervention (i.e., α=1). After scaling up the attention head outputs by a factor of α (x-axis):
(1) Modality-agnostic router head promotes the answers corresponding to the target modality; (2) Image promotion head always promotes the answers about image information; (3) Caption promotion head always promotes the answers about caption information.. |
2. Cross-Dataset Generalization of Router Heads \& Promotion Heads |
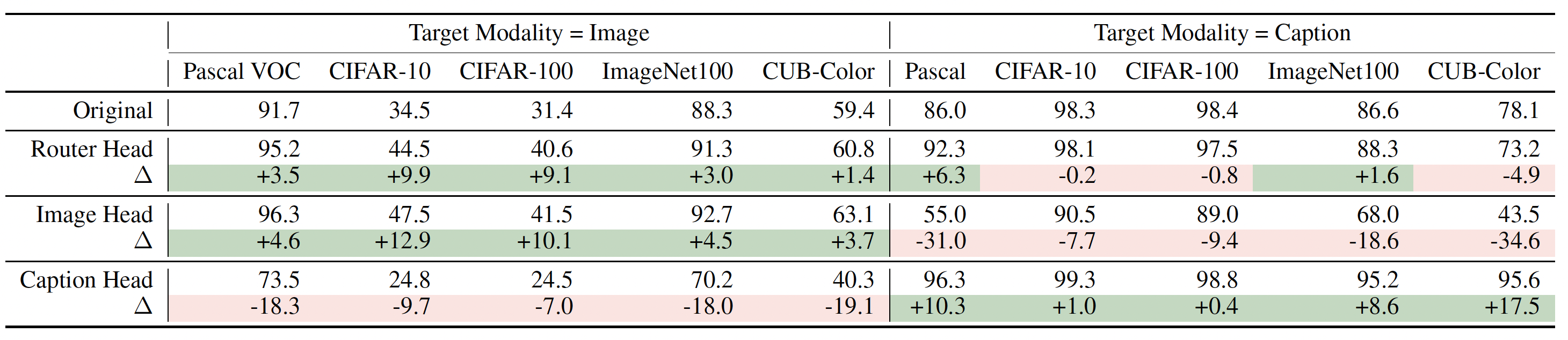 |
|
Cross-dataset generalization of modality-agnostic router head (L11H14), image promotion head (L19H26), and caption promotion head (L13H26) of Qwen2.5-VL. Δ computes the difference between the original model performance and the model performance with an attention head intervened. The router head can generalize across majority of the tasks, except CUB-Color. The image/caption promotion heads invariantly improve model's capability on reporting the corresponding modality's information. |
3. Effects of Attention Head Intervention on Representational Salience |
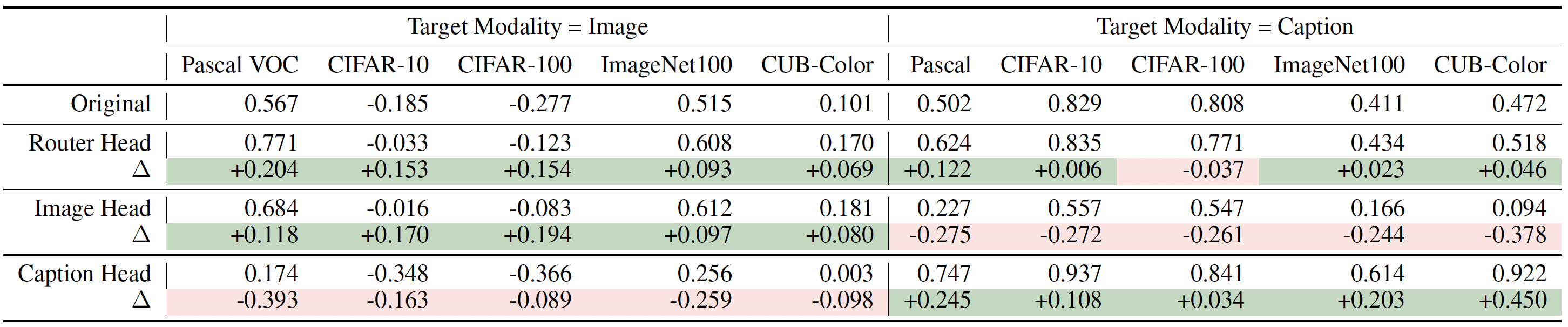 |
|
Effect of intervening router head (L11H14), image promotion head (L19H26), or caption promotion head (L13H26) of Qwen2.5-VL on V-Measure difference between the target and non-target modality. Δ is the difference between the original model and the model with different intervened heads. In general, attention head intervention will make the information of corresponding modality more salient in the representational space. We also observe a positive correlation between the change in V-Measure difference and the change in model’s performance. |
 |
Tianze (Etha) Hua*, Tian Yun*, Ellie Pavlick. How Do Vision-Language Models Process Conflicting Information Across Modalities? Under Review. |
|
AcknowledgementsThis template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here. |